最近在各个行业技术会议上,出现了越来越多的人工智能与测试结合的topic。比如最近几个跟人工智能相关的内容。
议题
公司
基于AIGC的蚂蚁新一代测试用例自动生成技术
蚂蚁集团
百度单元测试智能生成实践
百度
基于代码地图的组件测试用例自动生成实践
华为
类chatGPT大语言模型在自动化测试的前沿应用与案例分享
腾讯
大模型助力智能单测生成
字节跳动
华为云基于失败率预测及优化算法的回归用例优选一精准测试实践
华为云
人工智能与测试的结合话题风头一度盖过了精准测试,无疑成为了2023年测试行业最亮的技术方向。为什么人工智能会突然爆火,又会给大家带来哪些价值呢?接下来给大家做个分析。
为什么人工智能与测试的结合话题开始火爆
第一个推动力是无疑是chatgpt,它从年初一直火爆到现在,大语言模型(LLM)给我们提供了一个非常强大的人机交互方式,让机器的语言理解能力追上了人类,它能相对准确的理解人类语言,并基于GPT的方式为用户提供准确的预测结果。他恐怖的一百层以上的神经网络具备千亿级别以上的参数,这意味着人类复杂的多语言体系他已经可以信手拈来了。这么复杂的人类语言可以掌握,那么作为编程语言更是不在话下,在chatgpt推出后,基于代码分析的codex项目也自然顺势推出。具备敏锐嗅觉的github很快与openai合作推出了IT届的王炸 GitHub Copilot,实现了文生代码、代码转换、代码补全等各种炸裂效果。随着文生文、文生图、文生视频、文生直播的火爆,不少客服、设计、文案被淘汰。有2家公司的人告诉我,因为使用了人工智能效率提升,公司裁掉了部分岗位的80%的人员,只留下少部分的设计专家与使用人工智能的人员。Openai的创始人也明确说明了,人工智能会显著地影响就业。基本上可以预见,一个会写代码的超级智能体将会诞生,帮我们实现比较大的效率提升,同时也会给测试与开发圈带来比较大的影响。
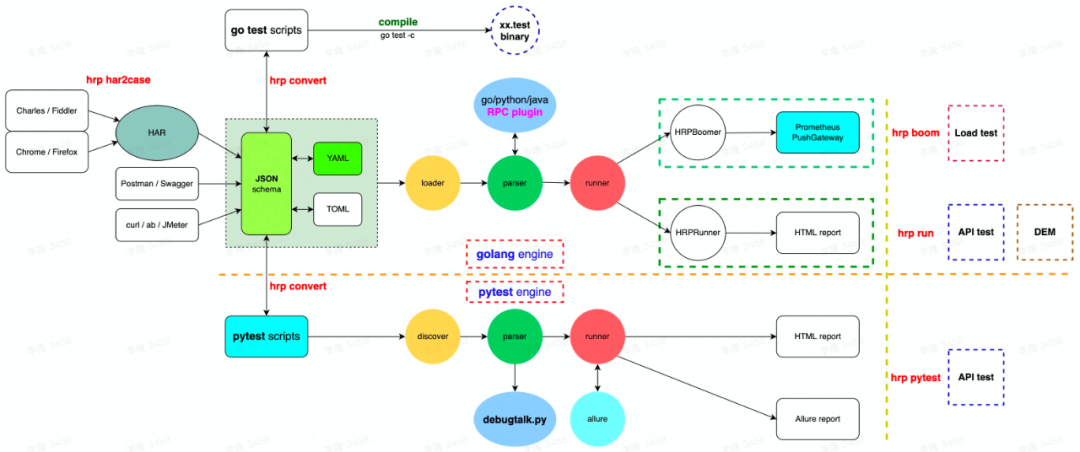
第二个推动力是测试生成技术的发展,测试技术的发展先后经历了测试用例数据驱动、测试用例自动生成等发展阶段。测试用例数据驱动使用yaml、json等数据化手段来实现自动化测试,比如国内李隆开源的httprunner,就是一个典型的数据驱动测试框架,用户使用数据驱动可以更简单更容易的维护测试体系,降低了使用成本,提高了测试效率,提高了测试的可维护性。测试用例自动生成技术则是通过转化其他的输入源比如har抓包数据、openapi接口规范、ui dom结构等数据到测试用例,实现测试用例的自动生成。测试用例的数据化与生成技术可以让测试人员扩大自己的能力边界,实现更全面的测试体系构建,它是测试智能化的一个重要的技术。
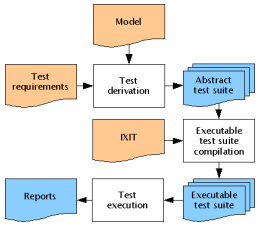
第三个推动力是模型驱动测试技术的崛起,模型驱动这个概念其实诞生很久了,但是因为本身需要一定的建模能力,无论是通过数学公式、有限状态机、或者有向图、知识图谱等技术,都是具备一定门槛的,所以模型驱动测试一直未在行业里得到大范围的推广。制约模型驱动测试的发展的另外一个因素是生态,行业里已经有一些模型驱动测试的工具了,比如graphwalker之类的,但是使用上不够简单,交流也少。一些bdd、atdd测试框架比如cucumber、RobotFramework等也想构建领域模型,只是没有完全做到,导致了行业里应用模型驱动测试比较难。
看似没有什么联系的三个方向在2023年突然就破局了。大语言模型LLM代表的是业务知识认知能力,测试用例生成技术是融合了测试设计与测试执行分析的关键测试落地技术,有了类似chatgpt这样的人类语言理解能力与代码理解能力,自然就可以去搞测试用例的生成,无论是手工测试,还是自动化测试。所以第一个爆发点就是测试用例的理解与生成。
领域模型与模型驱动
但是如果事情就这么简单,就不会有我提到的第三个推动力了。直接使用大语言模型去生成测试用例,是可以做到,但是不够完备。它无法严密的按照测试领域的规则去生成我们想要的内容,只能生成demo级别的场景,之所以如此,第一个原因是因为大语言模型缺乏测试专业的完整训练,第二个是缺乏合适的提示词引导。缺乏测试领域完整训练这个瓶颈需要通过提供足够的业务和领域资料进行微调(Fine-tuning),涉及到安全性和隐私问题,自然离不开本地的大语言模型部署,第二个瓶颈的解决则需要靠不断优化提示词工程技巧,这是个长期的过程。如果坚持从业务文档直接生成测试用例这个方向,无疑会是一个投入产出比例不确定的大坑。那如何解决这个问题呢?正好就是我提到的第三个推动力模型驱动测试方向。
大语言模型本身的输出是片段的,无法很好的生成测试体系完整结构,所以他是适合补充和完善细节。测试用例又是一个严谨的工程,两者直接转化的效果是不会太好的。这个时候我们就可以加入一个中间层。让大语言模型帮我们生成可以解释的中间结构体,然后我们通过中间结构体就可以很好的实现测试用例的生成与推理了。这层中间结构要易于维护、易于理解、支持增量更新不断完善,同时要具备可编程、可推理。能满足这些特点的技术,其实就是我前面提到的模型驱动测试。正确的做法是先由大语言模型生成领域模型,再根据领域模型生成可执行的测试用例。有了这层中间模型,很多之前无法很好实现的事情就可以落地了。
而领域模型的构建方式,比较常用的办法就是知识图谱。
人工智能会如何影响软件测试
手工测试用例生成,以前我们通过excel、思维导图、jira、禅道等工具管理测试用例,这种方式其实都是有问题的。手工测试虽然看起来简单,但是它仍然是一个严谨的工程师,登录帐号、测试数据与后续的测试用例存在逻辑关联,这些关联通常会散乱的管理,excel与jira、禅道等工具本质是通过简单的一维列表的方式管理的,具备一点点的层次结构展现而已。手工测试的用例维护问题是很多公司比较头痛的问题,我之前接到过多家银行的咨询请求,其中一个比较集中的问题就是手工测试用例的复用、继承、重载问题。如果手工测试用例没有很好的维护方式,到了一定规模就很难维护,就成了面子工程。这类问题的解决方案首先是要使用一个优秀的用例框架,用于构建用例模型,思维导图是早期大家用的一个方式,方向是靠谱的,只是形式不太合适,使用模型驱动+数据驱动的方式,就可以很好的维护了。手工测试用例中业务模型的生成,就可以利用大语言模型生成了。把推理和路径分析交给业务模型去完善。

自动化测试用例生成,跟手工测试用例生成是类似的过程,区别在于手工测试用例是由领域模型结合人类语言规则生成,而自动化用例是领域模型结合自动化领域的模型进行生成。自动化测试依赖更细节的接口与UI的定义,所以除了领域模型,我们还得提供